In data processing, the volume of data can be so large that the amount of time it takes to process a file matters. In my work, I try to optimise such jobs so that it is more efficient, but surprisingly, it is often not the business logic that is the bottleneck, but the parsing of files itself that consumes large amounts of CPU and memory.
Memory usage
Memory in particular can be a serious problem because we store files in S3 where the pricing model and latency of GET queries favours the storage of large files in the hundreds of MBs each.
The danger with storing such large files, however, is we can run out of memory just trying to parse them.
To illustrate the problem, here is a sample program that parses a JSON file and reports how much memory it uses before exiting.
import Control.Monad
import Data.Aeson
import GHC.Stats
import System.Posix.Process
import System.Process
import qualified Data.ByteString.Lazy as BS
import qualified System.Environment as IO
main :: IO ()
main = do
pid <- getProcessID
(filename:_) <- IO.getArgs
bs <- BS.readFile filename
let !maybeJson = decode bs :: Maybe Value
system $ "ps aux | grep " <> show pid <> " | grep -v grep"
forM_ maybeJson $ \_ ->
putStrLn "Done"This program is used to parse a 25MB file as follows:
$ git clone git@github.com:haskell-works/blog-examples.git
$ cd blog-examples/simple-json
$ stack build
$ curl https://data.medicare.gov/api/views/ijh5-nb2v/rows.json\?accessType\=DOWNLOAD > hospitalisation.json
$ ls -lh hospitalisation.json
-rw-r--r-- 1 jky staff 25M 24 Jul 22:00 hospitalisation.json
$ stack exec simple-json hospitalisation.json
jky 32237 394.0 1.9 1078037040 323084 s001 S+ 10:05pm 0:03.79 /Users/jky/wrk/haskell-works/blog-examples/simple-json/.stack-work/install/x86_64-osx/lts-12.2/8.4.3/bin/simple-json hospitalisation.json
DoneThe program self-reports that after parsing the file, it is using 394MB of memory!
$ time gzip hospitalisation.json
gzip hospitalisation.json 0.55s user 0.02s system 96% cpu 0.595 totalThe discrepancy is even larger if we consider that large files stored in S3 are often compressed:
$ gzip hospitalisation.json
$ ls -lh hospitalisation.json.gz
-rw-r--r-- 1 jky staff 4.5M 24 Jul 22:00 hospitalisation.json.gzSo now we’re look at unzipping and then parsing at a memory cost of 394M, or 87x the size of the compressed 4.5MB file or 16x the the size of the original 25MB file.
Why does this happen
JSON is hardly a compact serialisation format to start with, so the amount of memory required for parsing is quite astonishing.
Let’s take a look at the data type that describes that data that composes a typical JSON document:
data Json
= JsonString String
| JsonNumber Double
| JsonObject [(String, Json)]
| JsonArray [Json]
| JsonBool Bool
| JsonNull
deriving (Eq, Show)This can be explained by the cost of pointers.
A large document, will have lots of pointers connecting all the JSON nodes and they cost 64-bits each on modern CPU architectures.
The image below constrasts the amount of memory allocated to actual data (green) versus the amount of memory allocated to pointers (purple) and other housekeeping information maintained by the runtime (blue).
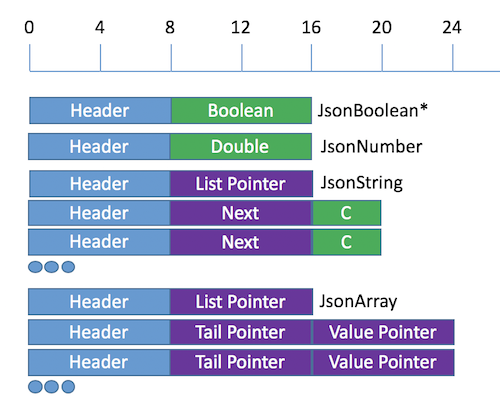
The header exists because the Json type is a tagged type and the runtime needs a place to store additional information (the tag) to know which constructor is relevant for interpreting the payload.
- A
JsonBoolcould theoretically be represented by one bit if represented as an unboxed and packed 1-bit integer. But given that Haskell’sBoolis a data type with two constructors, it is likely to be represented as a pointer to aTrueorFalsevalue as depicted here in green following the header, totalling 16-bytes. - A
JsonNumbermight be represented in 8 bytes, but with the header, it is still 16-bytes. - A
JsonStringis especially egrerious especially because it uses theStringtype but other representations likeText, whilst improvement, still leaves a lot of overhead. - A
JsonArrayis going to introduce a lot of overhead, because the payload typically is typed with[Json], and the cons cells use to construct a list will use a lot of memory for headers and pointers per element. Imagine how much member an array like [1,2,3,4,5] would use!
More information our how GHC allocates memory can be found here.
Hopefully, these examples have convinced you of the absurdity of using in-memory documents to represent large datasets.
CPU usage and IO boundedness
Another point of consideration when parsing large datasets is how long it takes to parse the file. Often we would just dismiss the slowness to the parsing being IO bound, but is it really?
Here we measure how long it takes to parse a 25MB JSON file (on my Macbook Pro):
$ time stack exec simple-json hospitalisation.json > /dev/null
stack exec simple-json hospitalisation.json > /dev/null 2.96s user 1.21s system 328% cpu 1.270 totalAt 8.44 MB/s (from 25 MB / 2.96 s), is that fast or close to IO bound?
Not even close.
Below, we see that command line tool cut can select the first two columns out of a CSV file at a rate of 76MiB/s, almost an order of magnitude faster.
Are we IO bound yet?
Other programs are faster. For example:
Character count:
Line count:
Or remove wc altogether so we just have cat and pv:
It’s probably safe to say, JSON parsing with a traditional style parser will, depending on the specifics of the hardware, be one to three orders of magnitude slower than speeds where it could be considered to be IO bound.
Where to from here
In the near future, I’d like to describe on this blog how the haskell-works parsing libraries address these and other problems, and future directions the libraries might take.
Among the topics I hope to explore are:
- how succinct data-structures can be used to parse files with a lot less memory
- how succinct data-structures look internally
- how to create a semi-index into files so that work used to parse a file can be re-used by later jobs
- how the laziness of the Haskell language can be exploited to avoid parsing unused data
- how validation, indexing and parsing can be different steps
- how validation and indexing can be parallelised
- how simd and bit-manipulation instructions can be used to optimise parsing and succinct data-structures